selenium+ requests自动化爬虫
今天接了一个爬虫的小项目。爬取一本书。内容并不是文字。全都是图片。
直接用requests比较难,于是就打算用selenium配合requests爬取。
以前没怎么用过selenium,也不咋熟悉,不过最后还是达到了要的效果。
爬取的网站:
https://book.yunzhan365.com/zaidx/jiah/mobile/index.html
seleminue环境配置
selenium安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium(使用清华园镜像下载)
webdriver下载
下载地址:http://chromedriver.storage.googleapis.com/index.html
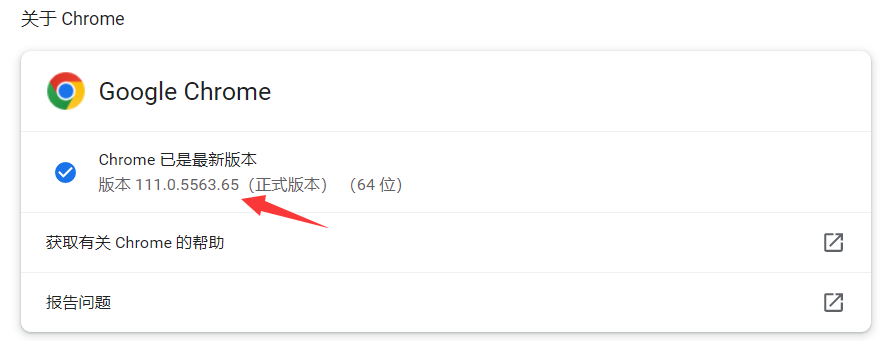
检查自己谷歌浏览器的版本,下载和谷歌浏览器版本一样的。

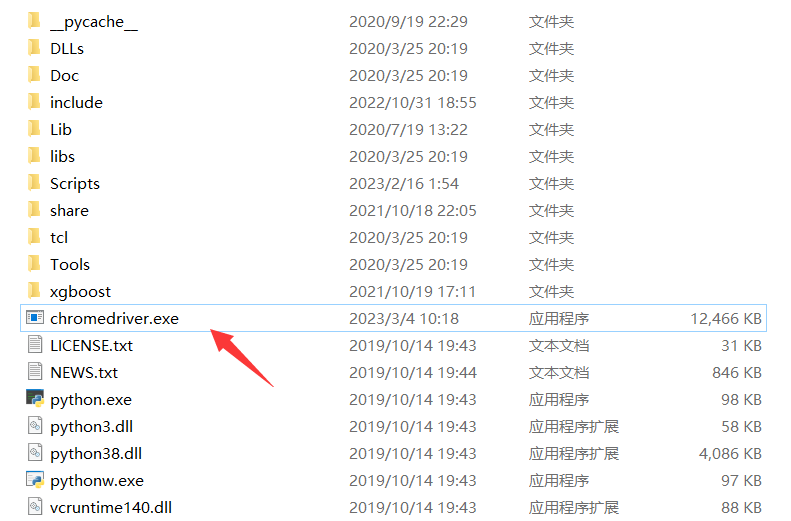
下载完成后解压,把chromedriver.exe这个文件放到python的安装目录中。
环境变量配置
打开系统环境变量,找到Path新建一个,把chromedriver.exe所在的目录放上去。

爬虫整体的思路
首先观察主界面,有上下页按钮。点击下一页按钮,查看对应的网络请求,
发现没有返回任何有用的信息。
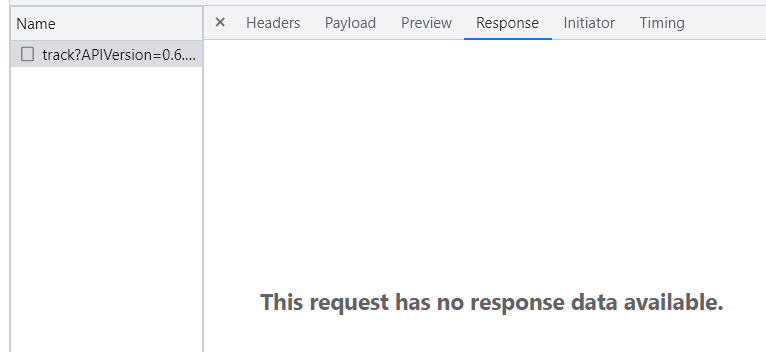
查看img栏,发现了图片的url。
https://book.yunzhan365.com/zaidx/jiah/files/large/6d0b462c813d6fff0cda410c17a54440.jpg?x-oss-process=image/resize,h_530,w_375/format,webp&1671693968
观察了这些图片的url,只有6d0b462c813d6fff0cda410c17a54440.jpg是变换的。
只要找到全部正文图片的url,就可以了。主要问题是怎么找到全部的图片url。
如果只用requests我都不知道咋办。好在selenium的DesiredCapabilities类可以记录每次点击所产生的url。
所以整体的思路就是通过selenium找到下一页按钮,进行自动点击,记录每次点击所产生的url。
然后在用正则匹配出书本正文图片的url。按页码排序放到一个列表中,在用requests请求下载。
具体代码实现
导入用到的库
import requests
import json,re,time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities匹配图片url的正则表达式
pattern = r'https://book\.yunzhan365\.com/[^/]+/[^/]+/files/large/[a-f0-9]+\.jpg\?x-oss-process=image/resize,h_\d+,w_\d+/format,webp&\d+'开启性能日志,记录
caps = DesiredCapabilities.CHROME
caps['goog:loggingPrefs'] = {'performance': 'ALL'}all_url 用来保存全部的图片url,我手动将前三张图片url放到列表中了
all_url = [
"https://book.yunzhan365.com/zaidx/jiah/files/large/47d5f6c73a4b353be27433dc88e30cea.jpg?x-oss-process=image/resize,h_560,w_396/format,webp&1671693968",
"https://book.yunzhan365.com/zaidx/jiah/files/large/0109adca58e0b5448c672b496c42d700.jpg?x-oss-process=image/resize,h_560,w_396/format,webp&1671693968",
"https://book.yunzhan365.com/zaidx/jiah/files/large/3621a25ed04e97eaf99f9fbe17b1b5f8.jpg?x-oss-process=image/resize,h_560,w_396/format,webp&1671693968"
]创建一个Chrome浏览器实例,并打开要爬取的网页
web = Chrome()
web.get('https://book.yunzhan365.com/zaidx/jiah/mobile/index.html')实现自动化点击并记录书本正文图片url
# 总共600张,每页显示两张图片。所以循环300次
for i in range(300):
time.sleep(3) # 暂停三秒,等浏览器加载完,否则后面可能找不到点击按钮
temp_url = [] # 临时图片url列表
next_page = web.find_element(By.XPATH,'//*[@class="buttonBar"]/div[3]') # 通过xpath找到下一页点击按钮
next_page.click() # 点击
logs = web.get_log('performance') # 获取日志
for log in logs:
log_entry = json.loads(log['message'])['message'] # 将日志信息转换为字典
if log_entry['method'] == 'Network.requestWillBeSent': # method属性为Network.requestWillBeSent就可以提取请求的url
url = log_entry['params']['request']['url'] # 提取url
if re.match(pattern, url): # 通过上面的正则表达式判断当前url是不是正文图片的链接
if url not in all_url: # 不存在全部url才添加
temp_url.append(url)
if temp_url: # temp_url 不为空才添加
temp_url.reverse() # 每页有两张图片链接,提取它们的时候页码位置就反了,所以把它们翻转一下
all_url += temp_url # 添加到全部的url列表中
time.sleep(1)requests请求图片url进行下载,并保存到本地
c = 1 #计数器,用来作为文件名
for book_url in all_url: # 遍历全部图片链接
img = requests.get(url=book_url.split('?')[0]).content # 请求图片链接返回图片二进制数据。图片链接以"?"分隔,去除后面的那些参数更加清楚一些
with open(f'./imgs/{c}.jpg','wb') as f: # 下载到本地
f.write(img)
time.sleep(0.2)
c += 1这样全书600页内容图片就下载完了。
完整代码
import requests
import json,re,time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
pattern = r'https://book\.yunzhan365\.com/[^/]+/[^/]+/files/large/[a-f0-9]+\.jpg\?x-oss-process=image/resize,h_\d+,w_\d+/format,webp&\d+'
caps = DesiredCapabilities.CHROME
caps['goog:loggingPrefs'] = {'performance': 'ALL'}
all_url = [
"https://book.yunzhan365.com/zaidx/jiah/files/large/47d5f6c73a4b353be27433dc88e30cea.jpg?x-oss-process=image/resize,h_560,w_396/format,webp&1671693968",
"https://book.yunzhan365.com/zaidx/jiah/files/large/0109adca58e0b5448c672b496c42d700.jpg?x-oss-process=image/resize,h_560,w_396/format,webp&1671693968",
"https://book.yunzhan365.com/zaidx/jiah/files/large/3621a25ed04e97eaf99f9fbe17b1b5f8.jpg?x-oss-process=image/resize,h_560,w_396/format,webp&1671693968"
]
web = Chrome()
web.get('https://book.yunzhan365.com/zaidx/jiah/mobile/index.html')
# 总共600张,每页显示两张图片。所以循环300次
for i in range(300):
time.sleep(3) # 暂停三秒,当浏览器加载完,否则后面可能找不到点击按钮
temp_url = [] # 临时图片url列表
next_page = web.find_element(By.XPATH,'//*[@class="buttonBar"]/div[3]') # 通过xpath找到下一页点击按钮
next_page.click() # 点击
logs = web.get_log('performance') # 获取日志
for log in logs:
log_entry = json.loads(log['message'])['message'] # 将日志信息转换为字典
if log_entry['method'] == 'Network.requestWillBeSent': # method属性为Network.requestWillBeSent就可以提取请求的url
url = log_entry['params']['request']['url'] # 提取url
if re.match(pattern, url): # 通过上面的正则表达式判断当前url是不是正文图片的链接
if url not in all_url: # 不存在全部url才添加
temp_url.append(url)
if temp_url: # temp_url 不为空才添加
temp_url.reverse() # 每页有两张图片链接,提取它们的时候页码位置就反了,所以把它们翻转一下
all_url += temp_url # 添加到全部的url列表中
time.sleep(1)
c = 1 #计数器,用来作为文件名
for book_url in all_url: # 遍历全部图片链接
img = requests.get(url=book_url.split('?')[0]).content # 请求图片链接返回图片二进制数据。图片链接以"?"分隔,去除后面的那些参数更加清楚一些
with open(f'./imgs/{c}.jpg','wb') as f: # 下载到本地
f.write(img)
time.sleep(0.2)
c += 1

发表评论
共 0 条评论
暂无评论