sklearn中的TF-IDF算法详解
TF-IDF介绍
sklearn中常用的文本特征提取方法TfidfVectorizer(),基于TF-IDF算法,算法包括两部分TF和IDF。
其中TF表示词频,IDF表示逆文档频率。TF * IDF就是TF-IDF了。
词频(TF)的计算公式为:

文章的总词数指的是某篇文章的总词数,不是整篇语料库里的词。
TfidfVectorizer,TfidfTransformer有个参数 smooth_idf
smooth_idf=True时,逆文档频率(IDF)的计算公式为:

smooth_idf=False时,逆文档频率(IDF)的计算公式为:

代码实现
from sklearn.feature_extraction.text import TfidfVectorizer,TfidfTransformer
import numpy as np
import pandas as pd
transformer = TfidfVectorizer()
counts = [
'这是 第一句 话',
'这是 什么 ',
'这是 测试 一条 语句'
'测试 一下'
]
tfidf = transformer.fit_transform(counts)
words = transformer.get_feature_names_out()
test = pd.DataFrame(tfidf.toarray(),columns=words)
#输出结果
一下 一条 什么 测试 第一句 语句 这是
0 0.000000 0.00000 0.000000 0.000000 0.842926 0.00000 0.538029
1 0.000000 0.00000 0.842926 0.000000 0.000000 0.00000 0.538029
2 0.000000 0.57458 0.000000 0.453005 0.000000 0.57458 0.366747
3 0.785288 0.00000 0.000000 0.619130 0.000000 0.00000 0.000000这是sklearn中的TfidfVectorizer计算的,我们现在套上面的公式计算一下 ‘这是 第一句 话’各个词的TF-IDF。
这句话总共有3个词,每个词都只出现了1次,所以TF为1/3。
总共有4篇文档
词 “这是” 出现在了3个文档中,IDF为log(4+1) / (3+1) + 1
词 “第一句” 出现在了1个文档中,IDF为log(4+1) / (1+1) + 1
所以,它们的TF-IDF 为:
1/3 * (log(4+1) / (3+1) + 1)
1/3 * (log(4+1) / (1+1) + 1 )
结果为:
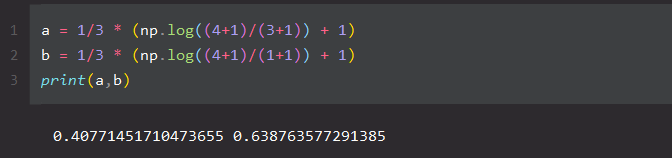
这好像和sklearn算的不一样,因为sklearn还做了归一化。
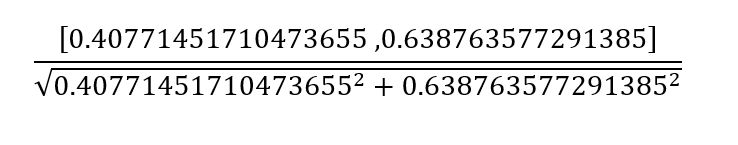
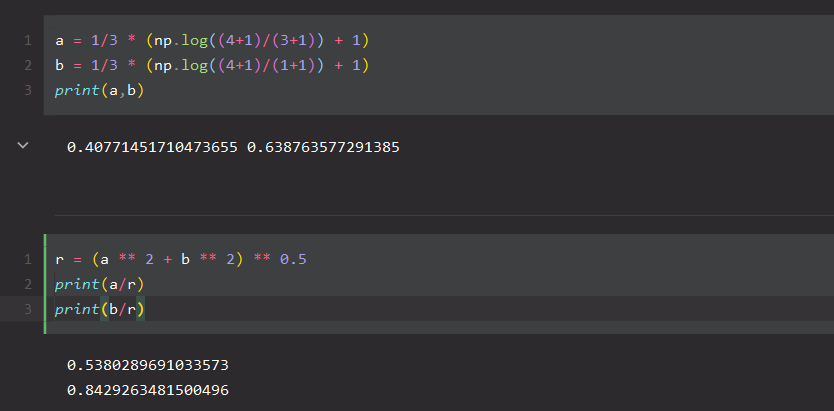
套公式到python计算,得到的结果和sklearn计算的一样了。
如果文章对你有帮助!可点击按钮打赏哦 ~


发表评论
共 0 条评论
暂无评论