超参数优化框架optuna
要训练一个好模型,训练数据很重要,超参数的选择也同样很重要。
为了选择合适的参数,不知道大家有没有写过这样的代码。
for i in [1, 3, 5, 7]:
for j in ['adam', 'sgd', 'rmsprop']:
for k in [8, 16, 32, 64]:
....虽然有用,但是浪费性能而且又不够优雅。
之前用的GridSearchCV网格搜索,感觉效率太低了,而且运行过程中,也没什么反馈,让我感觉程序在没在跑。
optuna简单好用,运行过程有足够的反馈,调参完事后还可以进行可视化!
安装
pip install optuna
pip install plotly # 可视化依赖的库使用
先看官网给的示例代码:
import sklearn
import optuna
# 1. Define an objective function to be maximized.
def objective(trial):
# 2. Suggest values for the hyperparameters using a trial object.
classifier_name = trial.suggest_categorical('classifier', ['SVC', 'RandomForest'])
if classifier_name == 'SVC':
svc_c = trial.suggest_float('svc_c', 1e-10, 1e10, log=True)
classifier_obj = sklearn.svm.SVC(C=svc_c, gamma='auto')
else:
rf_max_depth = trial.suggest_int('rf_max_depth', 2, 32, log=True)
classifier_obj = sklearn.ensemble.RandomForestClassifier(max_depth=rf_max_depth, n_estimators=10)
...
return accuracy
# 3. Create a study object and optimize the objective function.
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)是不是很简单,几行代码搞定。
以逻辑回归的超参数优化为例,实现代码如下:
X_train, X_test, y_train, y_test = train_test_split(X,Y, test_size=0.2, random_state=42)
# 目标函数
def objective(trial):
# 超参数搜索空间
C = trial.suggest_float("C", 1e-5, 1e+5, log=True)
max_iter = trial.suggest_int("max_iter", 100, 1500) # 100 - 1500之间的整数搜索
# 创建 LogisticRegression 模型
model = LogisticRegression(C=C, max_iter=max_iter, random_state=0)
model.fit(X_train, y_train)
#以测试集评分作为评估指标
scores = model.score(X_test,y_test)
# 返回模型测试集分数
return scores
# 创建实验对象
study = optuna.create_study(direction="maximize") #最大化测试集评分
study.optimize(objective, n_trials=100) # 执行100次实验
在执行过程中,还会有这些输出:
[I 2023-11-06 12:08:39,223] Trial 95 finished with value: 0.9458737383732436 and parameters: {'C': 14.554157090131449, 'max_iter': 1018}. Best is trial 71 with value: 0.9486938452404512.
[I 2023-11-06 12:08:41,767] Trial 96 finished with value: 0.948199089649713 and parameters: {'C': 1.8418719715241394, 'max_iter': 1068}. Best is trial 71 with value: 0.9486938452404512.
[I 2023-11-06 12:08:45,374] Trial 97 finished with value: 0.9477538096180487 and parameters: {'C': 6.408437562468524, 'max_iter': 974}. Best is trial 71 with value: 0.9486938452404512.
[I 2023-11-06 12:08:47,625] Trial 98 finished with value: 0.9486443696813774 and parameters: {'C': 3.197611318728761, 'max_iter': 1252}. Best is trial 71 with value: 0.9486938452404512.
Trial 表示这是第一次试验,with value 就是当前试验得到的测试集评分,后面就是当前试验的参数。
Best is trial 表示最好的测试集评分在第几次试验里,后面是最好测试集评分的值。
# 获取最佳超参数配置
best_params = study.best_params
best_value = study.best_value
print("最佳超参数配置:", best_params)
print("最佳测试集分数:", best_value)
可视化
# 学习曲线,查看的目标函数值随着试验次数的增加而变化
optuna.visualization.plot_optimization_history(study)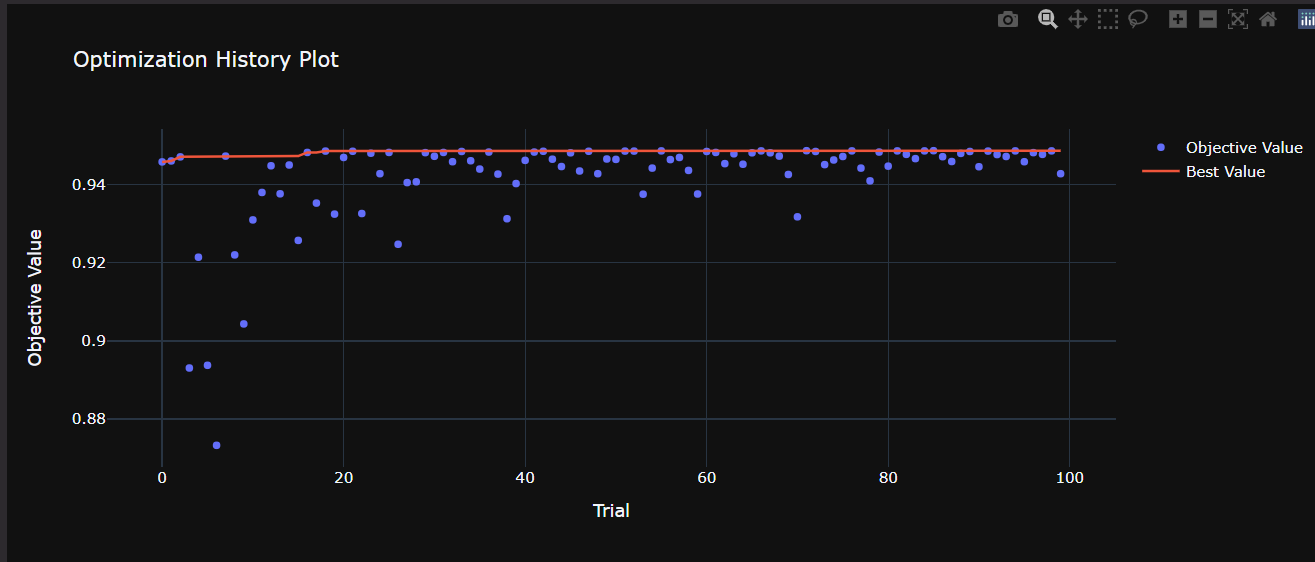
还有下面这些:
- 超参数重要性可视化: 绘制超参数的重要性图,查看哪些超参数对模型性能有更大的影响。使用 optuna.visualization.plot_param_importances(study) 来生成超参数重要性图。
- 超参数分布可视化: 超参数的分布情况,包括最佳超参数配置的取值范围。使用 optuna.visualization.plot_slice(study) 来生成超参数分布图。
- 超参数联合分布可视化: 可视化超参数之间的关联关系,以了解它们之间的相互影响。使用 optuna.visualization.plot_contour(study) 来生成超参数联合分布图。
- 多试验对比可视化: 比较不同试验之间的结果,以找到最佳的超参数配置。使用 optuna.visualization.plot_parallel_coordinate(study) 来生成多试验对比图。
如果文章对你有帮助!可点击按钮打赏哦 ~


发表评论
共 0 条评论
暂无评论